每日一报
TLA 的详细讲解与实现(ReadMe 的扩展与思考)
我们以如下代码为用例来探索一下各个构建工具在处理 TLA 时的表现:
// TLA.js
import { a } from './a';
import { b } from './b';
import { sleep } from './utils';
await sleep(1000);
console.log(a, b);
console.timeEnd('TLA');// a.js
import { sleep } from './utils';
console.time('TLA');
await sleep(1000);
export const a = 124;// b.js
import { sleep } from './utils';
await sleep(1000);
export const b = 124;// utils.js
export const sleep = (time) =>
new Promise((resolve) => {
setTimeout(resolve, time);
});对于上述例子来说,若通过 ESM Bundler(例如:Rollup、Esbuild)产物见如下:
// rollup-esm-output.js
const sleep = (time) =>
new Promise((resolve) => {
setTimeout(resolve, time);
});
console.time('TLA');
await sleep(1000);
const a = 124;
await sleep(1000);
const b = 124;
await sleep(1000);
console.log(a, b);
console.timeEnd('TLA');// utils.js
var sleep = (time) =>
new Promise((resolve) => {
setTimeout(resolve, time);
});
// a.js
console.time('TLA');
await sleep(1e3);
var a = 124;
// b.js
await sleep(1e3);
var b = 124;
// TLA.js
await sleep(1e3);
console.log(a, b);
console.timeEnd('TLA');Bun:
bun 会原封不动的将 TLA 编译到产物中去,同样也没有考虑兼容性,只考虑了现代浏览器的运行:
// utils.js
var sleep = (time) =>
new Promise((resolve) => {
setTimeout(resolve, time);
});
// a.js
console.time('TLA');
await sleep(1000);
var a = 124;
// b.js
await sleep(1000);
var b = 124;
// index.mjs
await sleep(1000);
console.log(a, b);
console.timeEnd('TLA');可以看出对于一般 ESM Bundler(例如:Rollup、Esbuild、Bun)来说,最终产物仅仅只是做到按照依赖顺序进行平铺处理,没有专门针对 TLA 的 ES2022 新特性的运行时处理,最后输出的产物并没有做到并发加载 async module。仅仅只是串行加载 async module,这改变了代码原始的语义。
根据提案我们可以将上述包含 TLA 模块进行如下方式转译:
// TLA.js
import { a, _TLAPromise as _TLAPromise_1 } from './a';
import { b, _TLAPromise as _TLAPromise_2 } from './b';
import { sleep } from './utils';
Promise.all([_TLAPromise_1(), _TLAPromise_2()])
.then(async () => {
await sleep(1000);
console.log(a, b);
console.timeEnd('TLA');
})
.catch((e) => {
console.log(e);
});// a.js
import { sleep } from './utils';
console.time('TLA');
export const _TLAPromise = async () => {
await sleep(1000);
};
export const a = 124;// b.js
import { sleep } from './utils';
export const _TLAPromise = async () => {
await sleep(1000);
};
export const b = 124;转译后通过 ESM Bundler(例如:Rollup、Esbuild、Bun)进行打包后的产物。
const sleep = (time) =>
new Promise((resolve) => {
setTimeout(resolve, time);
});
console.time('TLA');
const _TLAPromise$1 = async () => {
await sleep(1000);
};
const a = 124;
const _TLAPromise = async () => {
await sleep(1000);
};
const b = 124;
Promise.all([_TLAPromise$1(), _TLAPromise()])
.then(async () => {
await sleep(1000);
console.log(a, b);
console.timeEnd('TLA');
})
.catch((e) => {
console.log(e);
});// utils.js
var sleep = (time) =>
new Promise((resolve) => {
setTimeout(resolve, time);
});
// a.js
console.time('TLA');
var _TLAPromise = async () => {
await sleep(1e3);
};
var a = 124;
// b.js
var _TLAPromise2 = async () => {
await sleep(1e3);
};
var b = 124;
// TLA.js
Promise.all([_TLAPromise(), _TLAPromise2()])
.then(async () => {
await sleep(1e3);
console.log(a, b);
console.timeEnd('TLA');
})
.catch((e) => {
console.log(e);
});Bun 转译后的产物:
// utils.js
var sleep = (time) =>
new Promise((resolve) => {
setTimeout(resolve, time);
});
// a.js
var promise = async () => {
await sleep(1000);
};
var a = 124;
var _TLAPromise = promise;
// b.js
var promise2 = async () => {
await sleep(1000);
};
var b = 124;
var _TLAPromise2 = promise2;
// TLA.js
console.time('TLA');
Promise.all([_TLAPromise(), _TLAPromise2()])
.then(() => {
console.log(a, b);
console.timeEnd('TLA');
})
.catch((e) => {
console.log(e);
});此时 ESM Bundle 处理 TLA 模块遵循 TLA 规范。这就是 vite-plugin-top-level-await 插件所要做的事情,暂时缓解了 ESM Bundle 无法正确处理 TLA 规范的问题。
哪些工具实现了 TLA 规范
webpack:最早实现TLA规范的构建工具是webpack,仅需确保experiments.topLevelAwait配置项为true(从webpack版本5.83.0开始,默认启用此功能),且TLA为ESM模块,那么就可以正常编译TLA。Node:在ESM项目中实现了TLA。但本质上Node的执行与一般ESM Bundler不一样,并没有做打包处理,执行与浏览器有点相类似。浏览器
| Toolchain | Environment | Timing | Summary |
|---|---|---|---|
tsc | Node.js | node esm/a.js 0.03s user 0.01s system 4% cpu 1.047 total | b、c 的执行是并行的 |
tsc | Chrome |  | b、c 的执行是并行的 |
es bundle | Node.js | node out.js 0.03s user 0.01s system 2% cpu 1.546 total | b、c 的执行是串行的 |
es bundle | Chrome | 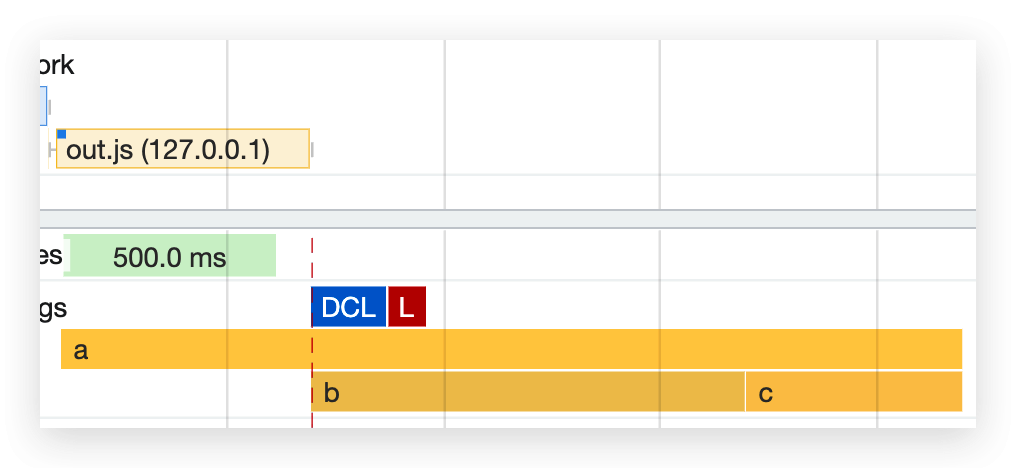 | b、c 的执行是串行的 |
Webpack (iife) | Node.js | node dist/main.js 0.03s user 0.01s system 3% cpu 1.034 total | b、c 的执行是并行的 |
Webpack (iife) | Chrome |  | b、c 的执行是并行的 |
总结
虽然 Rollup / esbuild / bun 等工具可以将包含 TLA 的模块成功编译成 es bundle,但是其语义是不符合 TLA 规范的语义的,现有简单的打包策略,会导致原本可以并行执行的模块变成了同步执行。只有 Webpack 通过编译到 iife,再加上复杂的 Webpack TLA Runtime,来模拟了 TLA 的语义,也就是说,在打包这件事上,Webpack 看起来是唯一一个能够正确模拟 TLA 语义的 Bundler。
webpack 实现 TLA 规范的原理
我们通过 webpack 来构建 TLA 模块,配置如下:
import path from 'path';
import { fileURLToPath } from 'url';
import { dirname } from 'path';
const __filename = fileURLToPath(import.meta.url);
const __dirname = dirname(__filename);
export default {
entry: './src/TLA.js',
output: {
filename: 'main.js',
path: path.resolve(__dirname, 'dist')
},
mode: 'production',
experiments: {
// 从 `webpack` 版本 5.83.0 开始,默认启用此功能
topLevelAwait: true
},
optimization: {
minimize: false
}
};可以看到输出的产物信息 webpack-tla-output.js(包含代码注释)。
webpack 实现 TLA 原理总结
TLA 模块具有传染性,TLA 模块的所有依赖方模块及依赖方的所有祖先模块也均为 TLA 模块。TLA 模块执行时,与往常一样(require)会 DFS 所有的 子依赖模块。不同的是对于 TLA 模块会通过 __webpack_require__.a 来进行初始化,当所有的子 TLA 模块均 resolve 完后会执行当前模块的 resolve 操作,当前模块 resolve 调的话就可以继续执行当前模块后续的内容。本质上就是模拟 Promise.all 的操作。
可以发现本质上 webpack 就是在模拟以下 这个流程。
import { a } from './a.mjs';
import { b } from './b.mjs';
import { c } from './c.mjs';
console.log(a, b, c);import { promise as aPromise, a } from './a.mjs';
import { promise as bPromise, b } from './b.mjs';
import { promise as cPromise, c } from './c.mjs';
export const promise = Promise.all([aPromise, bPromise, cPromise]).then(() => {
console.log(a, b, c);
});各个构建工具的 Chunk 生成算法
Rollup
Chunk 合并算法
概论介绍
- 依赖入口点: 入口模块集合 沿着依赖路径加载到 当前模块,则 入口模块集合 为 当前模块 的 依赖入口点。
- 副作用
- 指那些可能影响全局状态的操作,如全局函数调用、全局变量修改或可能抛出的错误。
- 算法将代码块分为纯粹的(无副作用)和非纯粹的(有副作用)。
- 相关副作用:
- 加载一个代码块时必然已经触发的所有副作用。
- 是所有依赖该代码块的入口点所加载的代码块的交集。
- 依赖副作用:
- 直接加载一个代码块时触发的副作用。
- 包括该代码块自身的副作用及其直接依赖的副作用。 :::
算法目标: 尝试通过合并小代码块到其他代码块中来消除小代码块。
合并的安全性考虑: 合并必须确保不会触发不应该被触发的副作用(全局函数调用、全局变量修改或可能抛出的错误等)。
合并规则:
- 如果每个代码块的 依赖副作用 是另一个代码块 相关副作用 的 子集, 则可以合并。
- 如果代码块
A的 依赖入口点 是代码块B的 子集, 且A的 依赖副作用 是B的 相关副作用 的子集, 则可以合并。
合并算法的两个阶段
- 第一轮:
- 尝试将小代码块
A合并到其他代码块B中,条件是A的 依赖入口点 是B的子集,且A的 依赖副作用 是B的 相关副作用 的子集。
- 尝试将小代码块
- 第二轮:
- 对于剩余的小代码块,寻找符合规则(
3-1)的任意合并机会,从最小的代码块开始。
- 对于剩余的小代码块,寻找符合规则(
- 第一轮:
额外考虑
合并时还需考虑避免加载过多额外代码。理想情况是小代码块的 依赖入口点 是另一个代码块 依赖入口点 的子集,这样可以确保在加载小代码块时,另一个代码块已经在内存中了。
让我们分析以下例子:
代码块定义:
- A, B, D, F: 有副作用
- C, E: 纯代码块(无副作用)
依赖关系:
- X -> A, B, C
- Y -> A, D, E
- A -> F
例子解释:
在上述图中:
- X 和 Y 是入口点
- 红色的块 (A, B, D, F, G, H) 表示有副作用的代码块
- 绿色的块 (C, E) 表示纯代码块(无副作用)
现在,让我们分析一下代码块 A 的相关副作用:
A 的依赖入口点:
- A 可以通过入口点 X 或 Y 被加载。所以 A 的依赖入口点是 ({X, Y})。
确定相关副作用:
- 当通过 X 加载 A 时,会加载: A, B, C, F, G
- 当通过 Y 加载 A 时,会加载: A, D, E, F, H
相关副作用的计算:
- A 的相关副作用是在任何可能的加载路径中(X 或 Y)都会出现的有副作用的代码块的集合。
- 这是上述两种加载路径的交集: ({A, F})。
因此,A 的相关副作用是 ({A, F})。这意味着无论何时 A 被加载,F 也一定会被加载,并且它们的副作用一定会被触发。
现在,让我们逐个分析每个代码块的相关概念:
A:
- 依赖入口点:
{X, Y} - 相关副作用:
{A, F} - 依赖副作用:
{A, F}
- 依赖入口点:
B:
- 依赖入口点:
{X} - 相关副作用:
{B} - 依赖副作用:
{B}
- 依赖入口点:
C:
- 依赖入口点:
{X} - 相关副作用:
{}(纯代码块) - 依赖副作用:
{}
- 依赖入口点:
D:
- 依赖入口点:
{Y} - 相关副作用:
{D} - 依赖副作用:
{D}
- 依赖入口点:
E:
- 依赖入口点:
{Y} - 相关副作用:
{}(纯代码块) - 依赖副作用:
{}
- 依赖入口点:
F:
- 依赖入口点:
{X, Y}(因为A依赖F,而X和Y都依赖A) - 相关副作用:
{A, F} - 依赖副作用:
{F}
- 依赖入口点:
现在,让我们考虑可能的合并:
合并F到A:
- 可以安全合并,因为F的依赖入口点({X, Y})与A的依赖入口点({X, Y})相同
- F的依赖副作用({F})是A的相关副作用({A, F})的子集
合并B到A:
- 不能安全合并,因为虽然B的依赖入口点({X})是A的依赖入口点({X, Y})的子集
- 但B的依赖副作用({B})不是A的相关副作用({A, F})的子集
合并C到B:
- 可以安全合并,因为C的依赖入口点({X})与B的依赖入口点({X})相同
- C是纯代码块,没有副作用,所以它的依赖副作用({})必定是B的相关副作用({B})的子集
合并E到D:
- 可以安全合并,原因与合并C到B类似
合并D到A:
- 不能安全合并,因为虽然D的依赖入口点({Y})是A的依赖入口点({X, Y})的子集
- 但D的依赖副作用({D})不是A的相关副作用({A, F})的子集
合并结果:
- 我们可以安全地将F合并到A中,因为F总是随A加载,且F的副作用已经包含在A的相关副作用中。
- 我们可以安全地将C合并到B中,以及将E合并到D中,因为它们是纯代码块,不会引入新的副作用。
- 我们不能将B或D合并到A中,因为这可能会在只需要A的场景下错误地触发B或D的副作用。
总结
通常情况下, 算法试图在保证应用正确性(特别是关于副作用)的同时,通过智能地合并小的代码块来优化整体加载性能。